
DMU, es una herramienta gratuita descargable y es el método oficialmente compatible para migrar Bases de datos de Oracle 12c y sus character set.
También admite la migración en las bases de datos anteriores como Oracle 11.2, 11.1 y 10.2.
Su línea de comando hereda las utilidades de CSSCAN y CSALTER que han sido deshabilitadas a partir de Oracle 12c. Además, viene integrada en una interfaz gráfica fácil de usar.
Las tareas desafiantes, como la de identificación de los problemas de datos, la aplicación de acciones de limpieza de datos, la conversión de datos, entre otras, con su entorno gráfico fácil de usar mantiene la carga de trabajo manual propensa a errores al mínimo.
La DMU le permite convertir solo los datos que deben convertirse, a nivel de tabla, columna y fila.
Para su instalación
- Habrá que usar una arquitectura JDK que coincida con la arquitectura del sistema operativo.
- Instalar el paquete PL/SQL requerido en la base de datos.
- La funcionalidad entre el cliente DMU y su función DMU están en el paquete SYS.DBMS_DUMA_INTERNAL, este paquete no está instalado por defecto y habrá que instalarlo. Posteriormente iniciaremos sqlplus con la sesión de SYSDBA e iniciar el script ?/rdbms/admin/prvtdumi.plb.
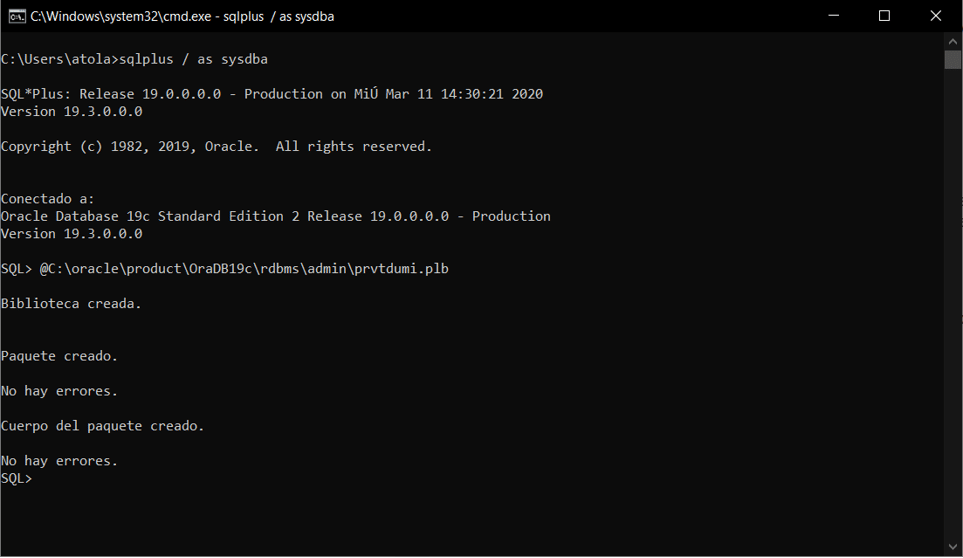
- Al finalizar el script en caso de no tener la versión 8 de JDK (Java SE Development Kit) tendremos que instalarlo.
- A continuación, procederemos a instalar el DMU descargándola desde la página OTN con su Patch#30149496 y con su licencia Standart OTN Developer License sin este Patch no podremos instalar el DMU.
- Iniciaremos el DMU usando dmuW32.exe o dmuW64.exe acode con la arquitectura del sistema en el que lo vayamos a instalar.
- Antes de poder conectarse a una base de datos de destino para comenzar el proceso de migración, debe definir una conexión proporcionando el nombre de usuario administrativo de la base de datos, su contraseña y los datos de conexión de la red: el nombre de host, el puerto TNS y el nombre de servicio de la base de datos. El usuario debe tener privilegios SYSDBA en la base de datos.
- Cuando conectas por primera vez pedirá que instale un repositorio de migración de DMU.
- Después de todo este proceso estará listo para comenzar el proceso de migración a Unicode. Escaneara la base de datos para identificar problemas de convertibilidad, limpiara la base de datos de estos problemas y ejecutara el paso de conversión real.
- También se puede usar la aplicación para comprobaciones periódicas para ayudar a detectar cualquier aplicación o problema de configuración ETL rápidamente, evitando que se acumulen datos ilegales en la base de datos.
Truncamiento de datos
Cuando la base de datos se crea utilizando la semántica de bytes, los tamaños de los tipos de datos CHAR y VARCHAR2 se especifican en bytes, no en caracteres.
Por ejemplo, la especificación CHAR (20) en una definición de tabla permite 20 bytes para almacenar datos de caracteres. Cuando el conjunto de caracteres de la base de datos utiliza un esquema de codificación de caracteres de un solo byte, no se produce pérdida de datos cuando se almacenan caracteres porque el número de caracteres es equivalente al número de bytes.
Si el conjunto de caracteres de la base de datos usa un conjunto de caracteres multibyte, entonces el número de bytes ya no es igual al número de caracteres porque un carácter puede constar de uno o más bytes.
Durante la migración a un nuevo conjunto de caracteres, es importante verificar los anchos de columna de las columnas CHAR y VARCHAR2 existentes, ya que es posible que tengan que ampliarse para admitir una codificación que requiere almacenamiento multibyte. El truncamiento de datos puede ocurrir si la conversión causa la expansión de datos.
Por ejemplo:

La primera columna de la tabla anterior muestra los caracteres seleccionados.
La segunda columna muestra la representación hexadecimal de los caracteres en el juego de caracteres WE8MSWIN1252.
La tercera columna muestra la representación hexadecimal de cada carácter en el juego de caracteres AL32UTF8. Cada par de letras y números representa un byte.
Por ejemplo, ä (a con una diéresis) es un carácter de un solo byte (E4) en WE8MSWIN1252, pero se convierte en un carácter de dos bytes (C3 A4) en AL32UTF8. Además, la codificación del símbolo del euro se expande de un byte (80) a tres bytes (E2 82 AC).
Si los datos en el nuevo character set requieren un almacenamiento que es mayor que el tamaño de byte admitido de los tipos de datos, entonces debe cambiar su esquema. Puede que necesite usar columnas CLOB.
Antes de cambiar el character set
Antes de cambiar el character set de una base de datos, es necesario identificar posibles problemas en la conversión de la misma en una base de datos y posibles truncamientos de datos.
El escaneo de datos identifica la cantidad de esfuerzo requerido para migrar los datos al nuevo esquema de codificación de caracteres antes de cambiar el conjunto de caracteres de la base de datos.
Algunos ejemplos de lo que se puede encontrar durante un escaneo de datos son el número de objetos de esquema donde los anchos de columna deben expandirse y la extensión de los datos que no existen en el repertorio de caracteres de destino. Esta información ayuda a determinar el mejor enfoque para convertir el conjunto de caracteres de la base de datos.
Una vez identificados los posibles problemas de datos, deben limpiarse adecuadamente para garantizar que la integridad de los datos se pueda preservar durante la conversión de datos.
El paso de limpieza de datos podría requerir mucho tiempo y esfuerzo dependiendo de la escala y la complejidad de los problemas de datos encontrados. Puede tomar múltiples iteraciones de escaneo y limpieza de datos para abordar correctamente todas las excepciones de datos.
Nota: La conversión de datos es el proceso mediante el cual los datos de caracteres se convierten del character set de origen en la representación del character set de destino.
La conversión incorrecta de datos puede provocar daños en los datos, por lo tanto, realice una copia de seguridad completa de la base de datos antes de intentar migrar los datos a un nuevo conjunto de caracteres.
Tenemos dos enfoques para la migración de character set:
- La migración usando Database Migration Assistant for Unicode.
- La migración usando la exportación e importación completa.
Esta versión del Asistente de migración de base de datos para Unicode tiene algunas restricciones con respecto a qué bases de datos puede convertir. En particular, no convierte bases de datos con ciertos tipos de datos convertibles en el diccionario de datos.
Los métodos de migración de exportación / importación podrían usarse para superar estas limitaciones.
Posibles problemas con el truncamiento de datos
Si los nombres de usuario o contraseñas existentes de Oracle se crean en función de los caracteres que cambian de tamaño en el nuevo conjunto de caracteres, entonces los usuarios tendrán problemas para iniciar sesión debido a fallas de autenticación después de la migración a un nuevo conjunto de caracteres.
Esto ocurre porque los nombres de usuario, las contraseñas que están cifrados y almacenados en el diccionario de datos, pueden no actualizarse durante la migración a un nuevo conjunto de caracteres. Por ejemplo, si el conjunto de caracteres de la base de datos actual es WE8MSWIN1252 y el nuevo conjunto de caracteres de la base de datos es AL32UTF8, entonces la longitud del nombre de usuario “scött” (o con una diéresis) cambia de 5 bytes a 6 bytes. En AL32UTF8, “scött” ya no puede iniciar sesión debido a la diferencia en el nombre de usuario. Oracle recomienda que los nombres de usuario y las contraseñas se basen en caracteres ASCII. Si no lo están, debe restablecer los nombres de usuario y contraseñas afectados después de migrar a un nuevo conjunto de caracteres.
En el diccionario de datos de la base de datos, los nombres de los objetos de esquema no pueden exceder los 30 bytes de longitud.
Debe cambiar el nombre de los objetos de esquema si sus nombres superan los 30 bytes en el nuevo character set de la base de datos.
Por ejemplo
Un carácter tailandés en el conjunto de caracteres nacional tailandés requiere 1 byte. En AL32UTF8, requiere 3 bytes. Si ha definido una tabla cuyo nombre tiene 11 caracteres tailandeses. El nombre de la tabla debe acortarse a 10 o menos caracteres tailandeses cuando cambie el conjunto de caracteres de la base de datos a AL32UTF8, ya que de otro modo excedería el límite.
- Cuando los datos CHAR contienen caracteres que se expanden después de la migración a un nuevo conjunto de caracteres. El relleno de espacio no se elimina durante la exportación de la base de datos de forma predeterminada. Esto significa que estas filas serán rechazadas al importarlas a la base de datos con el nuevo juego de caracteres. La solución consiste en establecer el parámetro de inicialización BLANK_TRIMMING en TRUE antes de importar los datos CHAR.
Pasos antes de la conversión (migración)
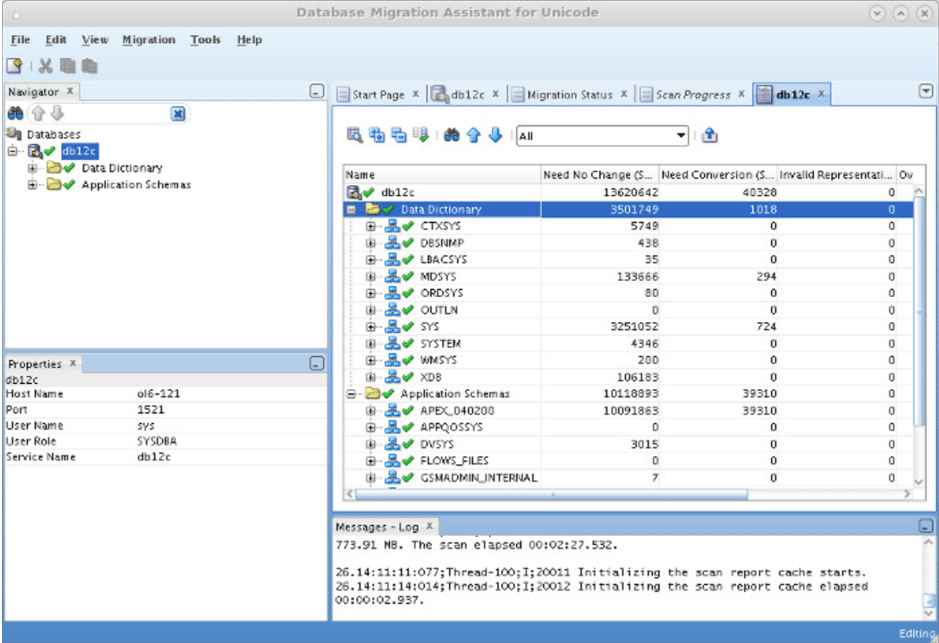
En el proceso de escaneo de la base de datos podremos ver los posibles problemas que pudieran suceder en el proceso de conversión y la cantidad de datos que necesitan ser convertidos y los que no.
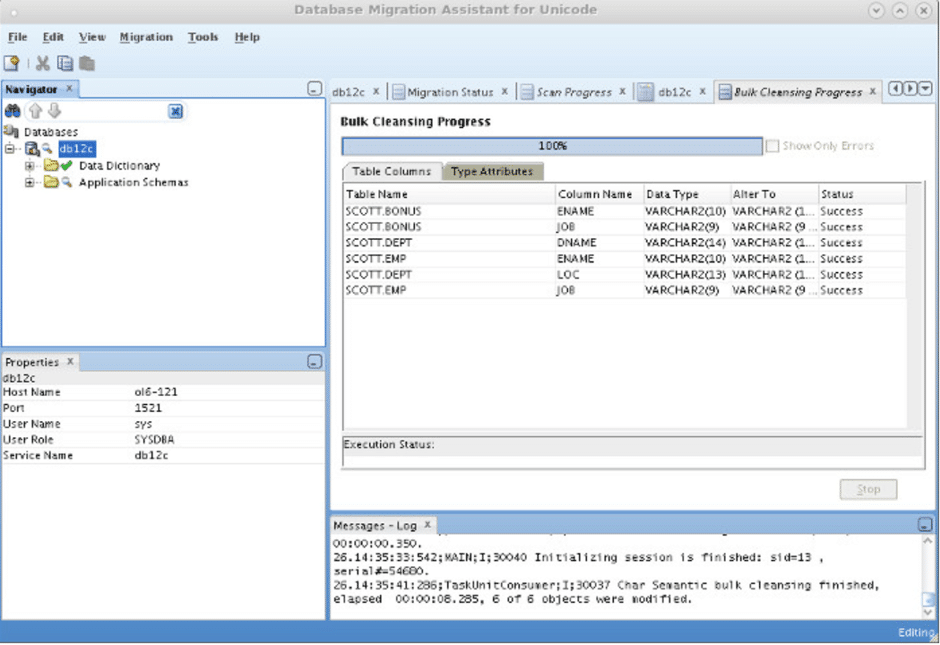
En el proceso de limpieza seleccionaremos los datos que vamos a limpiar y en que columna y que tipo de datos vamos a convertir a que.
Por ejemplo, si es necesario ampliar un varchar2 (10) a un varchar2 (10 CHAR) o a otro tipo de dato.
Podréis encontrar mas información y tutoriales acerca de bases de datos en nuestra página web.